This post is split into two parts. First we’re going to talk about how Ruby finds other files. Then, once we’ve got our head around that, we’re going to look at the extra sprinkles of magic that Rails adds on top.
(If you’re something of a Ruby magician already, and you’re just looking for the Rails bits, you can skip straight ahead to Part 2 - Loading Files in Rails)
Have you ever wondered: “How does Rails knows about all the classes in my app?”
Look at the code below:
# app/controllers/invoice_controller.rb
class InvoiceController < ApplicationController
# some business logic
end
How does your code know about ApplicationController? You never explicitly told Rails that ApplicationController existed, but it didn’t blink when it saw it for the first time.
Rails just seems to have a sixth sense for these sorts of things.

This will be extra confusing if you come from a language like Python or Javascript. In those languages, you generally need to add import statements to the top of every file specifying where to find code that you want to use (which can get pretty tedious).
How come Rails can get away without import statements? And is this a good thing or a bad thing? As we’ll discover, Ruby and Rails both have a few tricks that help us get around the tediousness of manually importing files
How we load files in Ruby
If you’ve written simple Ruby programs you’ll know that we do need to use the require method to load code from other files.
Here’s a nice Book class I wrote:
# book.rb
class Book
attr_reader :title
def initialize(title)
@title = title
end
end
And here’s a Bookshelf class (which obviously needs to know about Books):
# bookshelf.rb
class BookShelf
attr_reader :books
def initialize
@books = [Book.new('Catch 22')]
end
end
p BookShelf.new.books.map(&:title)
The two files are sitting next to each other in the same directory:
$: tree
.
├── bookshelf.rb
└── book.rb
Now, if we try and run $: ruby bookshelf.rb, we’ll get a NameError.
bookshelf.rb:7:in `initialize': uninitialized constant BookShelf::Book (NameError)
@books = [Book.new('Catch 22')]
Ruby has never heard of the Book class. 😞
But! If we add require './book' to the top of bookshelf.rb, the code runs successfully.
$: ruby bookshelf.rb
["Catch 22"]
So how does this work?
What does require do?
To understand require, we need to understand the $LOAD_PATH. The $LOAD_PATH is a Ruby global variable (notice the $) which references an array of strings. Each of the strings is the file path to a directory.
Here’s my $LOAD_PATH:
irb(main):003:0> puts $LOAD_PATH
/opt/homebrew/Cellar/rbenv/1.2.0/rbenv.d/exec/gem-rehash
/Users/olly/.rbenv/versions/2.7.2/lib/ruby/site_ruby/2.7.0
/Users/olly/.rbenv/versions/2.7.2/lib/ruby/site_ruby/2.7.0/arm64-darwin20
/Users/olly/.rbenv/versions/2.7.2/lib/ruby/site_ruby
/Users/olly/.rbenv/versions/2.7.2/lib/ruby/vendor_ruby/2.7.0
/Users/olly/.rbenv/versions/2.7.2/lib/ruby/vendor_ruby/2.7.0/arm64-darwin20
/Users/olly/.rbenv/versions/2.7.2/lib/ruby/vendor_ruby
/Users/olly/.rbenv/versions/2.7.2/lib/ruby/2.7.0
/Users/olly/.rbenv/versions/2.7.2/lib/ruby/2.7.0/arm64-darwin20
=> nil
When we call the require method below, Ruby will look in each of the directories listed in the $LOAD_PATH to try and find a file called byebug.rb in them.
irb(main):002:0> require 'byebug'
=> true
We can tell that it found one, because it returns true. If Ruby can’t find a byebug.rb file within those directories, it will throw a LoadError.
We can check that there definitely is a file called byebug.rb, if we run the following command from the console:
$: gem which byebug
/Users/olly/.rbenv/versions/2.7.2/lib/ruby/gems/2.7.0/gems/byebug-11.1.3/lib/byebug.rb
There it is! Ruby wasn’t lying.
Finding your own code
This is all nice and simple for gems like byebug. These files are automatically added to directories in the $LOAD_PATH. But what if we want to require some of our own code?
If you look at the directories listed in the $LOAD_PATH, you won’t see the directory of the current file1. This is a shame if you want to make an app with a bunch of related files and put them all in the same directory. Our Ruby files won’t be able to talk to each other.
There are a few ways to get around this, but first we need to understand the difference between:
- the working directory - the directory where we initiated the Ruby process (by running
ruby ruby_project/bookshelf.rb) and - the directory of the current file - where the Ruby file is located

Option 1 - require_relative
One option is to use require_relative.
# bookshelf.rb
require_relative 'book'
require_relative completely ignores the $LOAD_PATH and instead just searches for files in the current file’s directory (no matter what your working directory is).
Option 2 - plain, old require (with a '.')
Alternatively, we can use require with the ./ the syntax that we tried above.
# bookshelf.rb
require './book'
Adding ./ ( or ../) to the start of the argument we pass to require tells Ruby to search for the file in your working directory (where you started the ruby process). It also means Ruby completely ignores the $LOAD_PATH again.
Not really sure why you would want this behaviour (require_relative seems much simpler), but it’s there2.
Couldn’t we just amend the $LOAD_PATH?`
Alternatively, rather than bypassing the $LOAD_PATH as in the options above you can edit the $LOAD_PATH to add the current file’s directory to it (it’s just a mutable array after all).
Option 3 - edit the $LOAD_PATH
Here is a common pattern for this:
absolute_path_for_directory_of_current_file = File.expand_path('..', __FILE__)
$LOAD_PATH.unshift(absolute_path_for_directory_of_current_file)
Let’s unpack this a little bit.
__FILE__ is a relative path to the current file (eg bookshelf.rb) from the current working directory. So, the value of __FILE__ is going to be different depending on where you’re running your ruby process.
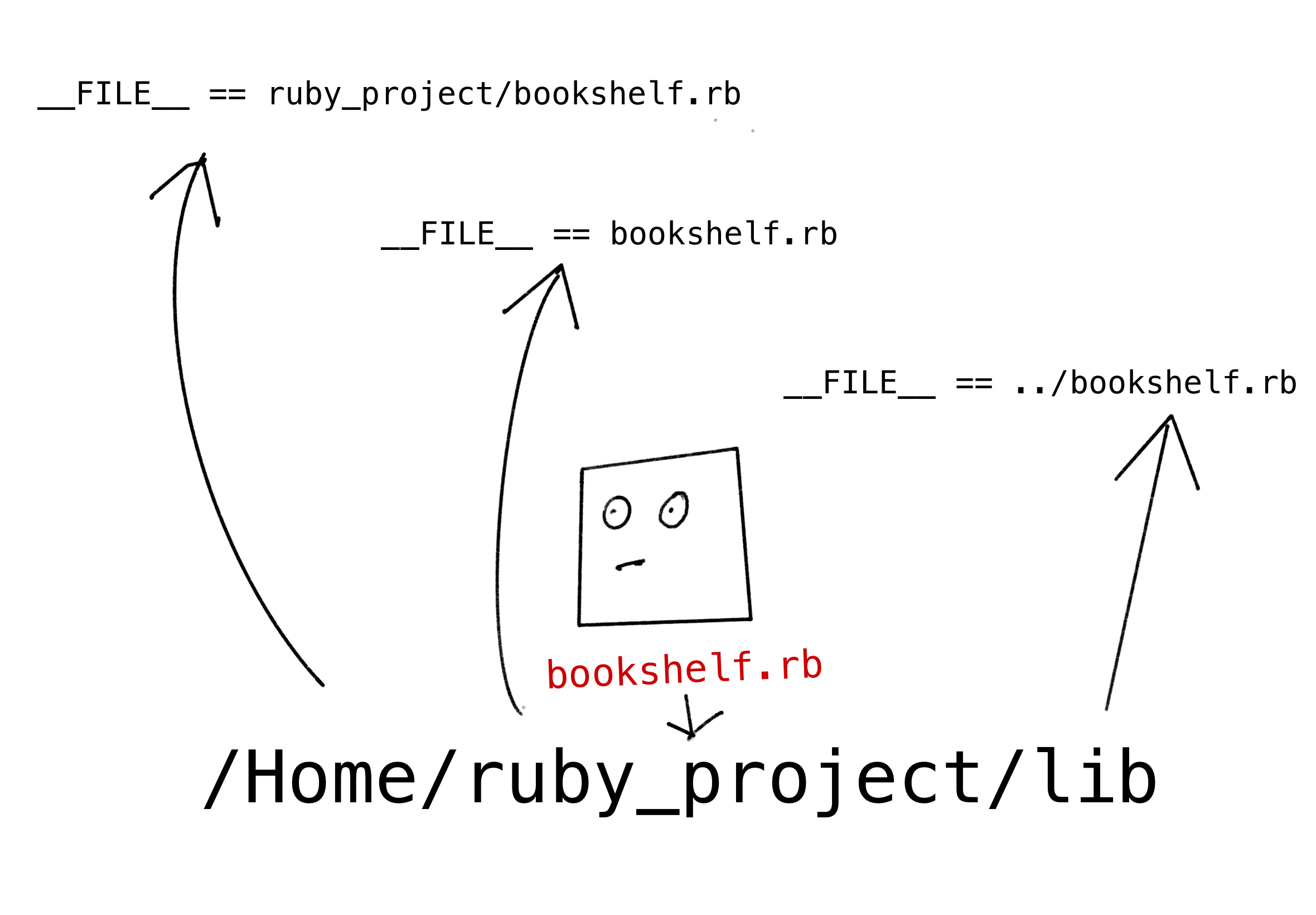
File.expand_path is a clever method that takes relative filenames and turns them into absolute filenames. So File.expand_path('..', __FILE__) will give us a an absolute path to the directory of the current file3. 🎉 Because it’s an absolute path, it will always be the same regardless of where on your machine you start your Ruby process.
Then we use Array#unshift to shove this absolute filename at the beginning of the $LOAD_PATH. Now, when you add require 'book' to the top of bookshelf.rb, Ruby will find our file when it goes hunting through the $LOAD_PATH.
Which approach should I use?
While require_relative works for small projects, amending the $LOAD_PATH is probably preferable for larger projects. With a lot of files spread across a number of directories, you probably don’t want the complexity of working out the relative file path for each of them.
What about load?
You may also have come across load. load does something very similar to require, but with a couple of differences.
require will only load a file once, no matter how many times you ask Ruby to reload it. (Ruby stores a list of the files it has already required in the $LOADED_FEATURES global variable. If a file is already in that list require will not reload it again.)
load isn’t as fussy. It will keep loading and reloading files as often as you ask it to (and doesn’t even bother consulting $LOADED_FEATURES).
So require tends to be used for loading libraries and modules (that you probably only want to load once), whereas load is used to load things that might change frequently (like configuration classes).
What about autoload?
OK, we’re nearly there. But to understand how Rails does it’s file loading magic, we need to understand one more aspect of file loading in Ruby: the autoload method.
autoload does an interesting thing that we haven’t seen yet: lazy loading.
When Ruby encounters the autoload keyword, it doesn’t load the file immediately. Instead it saves a reference to the two arguments it is passed: a filename and a class name. When it encounters that class for the first time, it will then load the file (and will assume that it will find the class defined within it).
Going back to our BookShelf example, we can pass autoload a symbol of the class we want to load (in this case :Book). Then if it encounters a class of that name, it will require the file that we passed in as the second argument (./book.rb).
# book.rb
class Book
attr_reader :title
puts("Loading the Book class")
def initialize(title)
@title = title
end
end
# bookshelf.rb
autoload :Book, './book.rb'
class BookShelf
attr_reader :books
def initialize
puts("Initializing a BookShelf")
@books = [Book.new('Catch 22')]
end
end
p BookShelf.new
=> "Initializing a BookShelf"
=> "Loading a Book class" # <- we don't load the Book class until Ruby encounters the Book constant for the first time
This allows lazy loading, which I guess is good if you’re worried about startup speed for your program. It means you don’t have to load a bunch of files before running any code.
(As an aside, autoload actually requires files rather than loading them. In other words, it only loads each file once. So it should be called autorequire - the world is imperfect in so many ways.)
We made it
Ok, there we are. Hopefully you now understand the different methods that Ruby uses to load files. But we’re really only just getting started.
In Part 2 of this post we’re going to look at how Rails uses these Ruby tricks (and a few others) to magically find classes that it has never even heard of before.
-
Fun fact!
'.'(the working directory) used to be in the$LOAD_PATHprior to Ruby 1.9.2, but was removed for security reasons. ↩ -
I think the reason we have both of these is that
require_relativewas only introduced in Ruby 1.9.2. The other syntax preceded it and nobody wanted to make a breaking change by removing it. ↩ -
The
'..'here means that we’ll get a path to the directory containing the file. Without this,expand_pathwill just return a path to the file itself, and Ruby will ignore this in the$LOAD_PATH. The$LOAD_PATHshould only contain paths to directories. ↩